반응형
http://sandsprite.com/blogs/index.php?uid=7&pid=57
| This is a free tool for the analysis of
malicious PDF documents. It also has some features that can make it
useful for pdf vulnerability development.
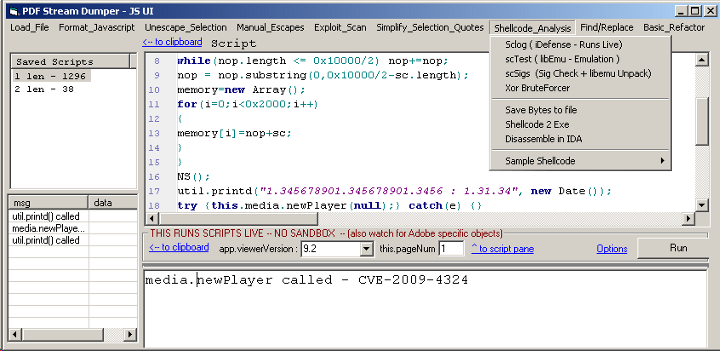
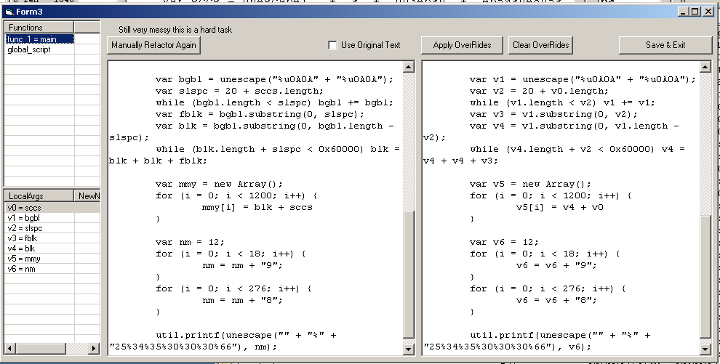
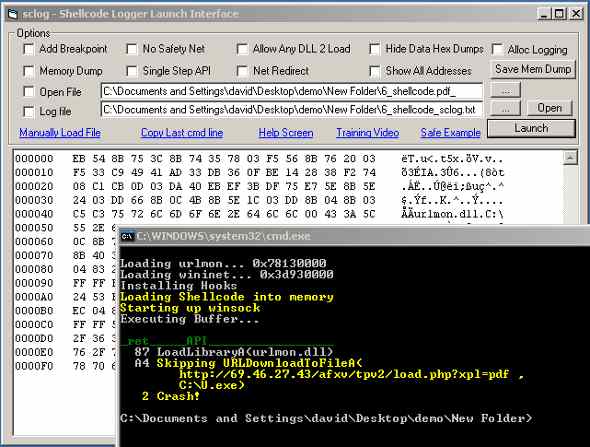
Has specialized tools for dealing with obsfuscated javascript, low level pdf headers and objects, and shellcode. In terms of shellcode analysis, it has an integrated interface for libemu sctest, an updated build of iDefense sclog, and a shellcode_2_exe feature. Javascript tools include integration with JS Beautifier for code formatting, the ability to run portions of the script live for live deobsfuscation, toolbox classes to handle extra canned functionality, as well as a pretty stable refactoring engine that will parse a script and replace all the screwy random function and variable names with logical sanitized versions for readability. Tool also supports unescaping/formatting manipulated pdf headers, as well as being able to decode filter chains (multiple filters applied to the same stream object.) Download: PDF Stream Dumper Setup 0.9.148 (includes full vb6 source) Training videos for PDFStreamDumper:
International users: This new build should now work on systems with extended character set languages set as their default language. If you encounter errors please let me know. Full feature list
Credits: 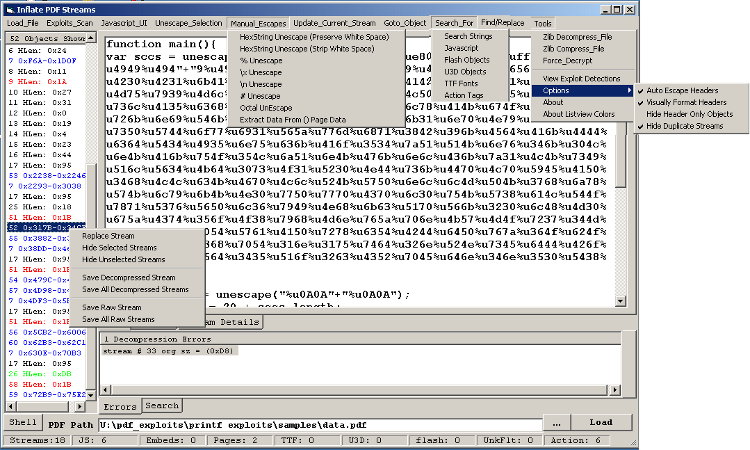
|
About Me Home Posts: |
||||||
Comments: (6)On 08.20.10 - 2:16pm Dave wrote:
On 08.21.10 - 4:43pm Dave wrote:
On 09.13.10 - 6:02am Dave wrote:
On 09.18.10 - 1:02pm Dave wrote:
On 09.25.10 - 4:44am dave wrote:
On 12.05.10 - 6:55am Dave wrote:
| |||||||
반응형
'작업공간 > 기본적인 삽질 & 기록' 카테고리의 다른 글
| Python tools for penetration testers (0) | 2011.01.10 |
|---|---|
| Google Hacking (0) | 2010.12.22 |
| Index of /re/unpacking (0) | 2010.12.18 |
| pdf analy (2) | 2010.12.13 |
| 내가 쓰는 Firefox Add-On (0) | 2010.12.10 |
 Tacettin_PDF_Malware_Analysis.pdf
Tacettin_PDF_Malware_Analysis.pdf